
Uintah and Related C-SAFE Publications
2017
![]()
S. Kumar, D. Hoang, S. Petruzza, J. Edwards, V. Pascucci.
“Reducing Network Congestion and Synchronization Overhead During Aggregation of Hierarchical Data,” In 2017 IEEE 24th International Conference on High Performance Computing (HiPC), pp. 223-232. Dec, 2017.
DOI: 10.1109/HiPC.2017.00034
Hierarchical data representations have been shown to be effective tools for coping with large-scale scientific data. Writing hierarchical data on supercomputers, however, is challenging as it often involves all-to-one communication during aggregation of low-resolution data which tends to span the entire network domain, resulting in several bottlenecks. We introduce the concept of indexing templates, which succinctly describe data organization and can be used to alter movement of data in beneficial ways. We present two techniques, domain partitioning and localized aggregation, that leverage indexing templates to alleviate congestion and synchronization overheads during data aggregation. We report experimental results that show significant I/O speedup using our proposed schemes on two of today's fastest supercomputers, Mira and Shaheen II, using the Uintah and S3D simulation frameworks.
![]()
B. Peterson, A. Humphrey, J. Schmidt, M. Berzins.
“Addressing Global Data Dependencies in Heterogeneous Asynchronous Runtime Systems on GPUs. Awarded Best Paper,” In Proceedings of the Third International Workshop on Extreme Scale Programming Models and Middleware - ESPM2'17, ACM, 2017.
DOI: 10.1145/3152041.3152082
Large-scale parallel applications with complex global data dependencies beyond those of reductions pose significant scalability challenges in an asynchronous runtime system. Internodal challenges include identifying the all-to-all communication of data dependencies among the nodes. Intranodal challenges include gathering together these data dependencies into usable data objects while avoiding data duplication. This paper addresses these challenges within the context of a large-scale, industrial coal boiler simulation using the Uintah asynchronous many-task runtime system on GPU architectures. We show significant reduction in time spent analyzing data dependencies through refinements in our dependency search algorithm. Multiple task graphs are used to eliminate subsequent analysis when task graphs change in predictable and repeatable ways. Using a combined data store and task scheduler redesign reduces data dependency duplication ensuring that problems fit within host and GPU memory. These modifications did not require any changes to application code or sweeping changes to the Uintah runtime system. We report results running on the DOE Titan system on 119K CPU cores and 7.5K GPUs simultaneously. Our solutions can be generalized to other task dependency problems with global dependencies among thousands of nodes which must be processed efficiently at large scale.
2016
![]()
J. Beckvermit, T. Harman, C. Wight, M. Berzins.
“Physical Mechanisms of DDT in an Array of PBX 9501 Cylinders Initiation Mechanisms of DDT,” SCI Institute, April, 2016.
The Deflagration to Detonation Transition (DDT) in large arrays (100s) of explosive devices is investigated using large-scale computer simulations running the Uintah Computational Framework. Our particular interest is understanding the fundamental physical mechanisms by which convective deflagration of cylindrical PBX 9501 devices can transition to a fully-developed detonation in transportation accidents. The simulations reveal two dominant mechanisms, inertial confinement and Impact to Detonation Transition. In this study we examined the role of physical spacing of the cylinders and how it influenced the initiation of DDT.
![]()
M. Berzins, J. Beckvermit, T. Harman, A. Bezdjian, A. Humphrey, Q. Meng, J. Schmidt,, C. Wight.
“Extending the Uintah Framework through the Petascale Modeling of Detonation in Arrays of High Explosive Devices,” In SIAM Journal on Scientific Computing , Vol. 38, No. 5, pp. S101-S122. 2016.
DOI: 10.1137/15M1023270
The Uintah framework for solving a broad class of fluid-structure interaction problems uses a layered taskgraph approach that decouples the problem specification as a set of tasks from the adaptove runtime system that executes these tasks. Uintah has been developed by using a problem-driven approach that dates back to its inception. Using this approach it is possible to improve the performance of the problem-independent software components to enable the solution of broad classes of problems as well as the driving problem itself. This process is illustrated by a motivating problem that is the computational modeling of the hazards posed by thousands of explosive devices during a Deflagration to Detonation Transition (DDT) that occurred on Highway 6 in Utah. In order to solve this complex fluid-structure interaction problem at the required scale, algorithmic and data structure improvements were needed in a code that already appeared to work well at scale. These transformations enabled scalable runs for our target problem and provided the capability to model the transition to detonation. The performance improvements achieved are shown and the solution to the target problem provides insight as to why the detonation happened, as well as to a possible remediation strategy.
![]()
A. Humphrey, D. Sunderland, T. Harman, M. Berzins.
“Radiative Heat Transfer Calculation on 16384 GPUs Using a Reverse Monte Carlo Ray Tracing Approach with Adaptive Mesh Refinement,” In 2016 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), pp. 1222-1231. May, 2016.
DOI: 10.1109/IPDPSW.2016.93
Modeling thermal radiation is computationally challenging in parallel due to its all-to-all physical and resulting computational connectivity, and is also the dominant mode of heat transfer in practical applications such as next-generation clean coal boilers, being modeled by the Uintah framework. However, a direct all-to-all treatment of radiation is prohibitively expensive on large computers systems whether homogeneous or heterogeneous. DOE Titan and the planned DOE Summit and Sierra machines are examples of current and emerging GPUbased heterogeneous systems where the increased processing capability of GPUs over CPUs exacerbates this problem. These systems require that computational frameworks like Uintah leverage an arbitrary number of on-node GPUs, while simultaneously utilizing thousands of GPUs within a single simulation. We show that radiative heat transfer problems can be made to scale within Uintah on heterogeneous systems through a combination of reverse Monte Carlo ray tracing (RMCRT) techniques combined with AMR, to reduce the amount of global communication. In particular, significant Uintah infrastructure changes, including a novel lock and contention-free, thread-scalable data structure for managing MPI communication requests and improved memory allocation strategies were necessary to achieve excellent strong scaling results to 16384 GPUs on Titan.
![]()
D. Sunderland, B. Peterson, J. Schmidt, A. Humphrey, J. Thornock, M. Berzins.
“An Overview of Performance Portability in the Uintah Runtime System through the Use of Kokkos,” In 2016 Second International Workshop on Extreme Scale Programming Models and Middlewar (ESPM2), IEEE, Nov, 2016.
DOI: 10.1109/espm2.2016.012
The current diversity in nodal parallel computer architectures is seen in machines based upon multicore CPUs, GPUs and the Intel Xeon Phi's. A class of approaches for enabling scalability of complex applications on such architectures is based upon Asynchronous Many Task software architectures such as that in the Uintah framework used for the parallel solution of solid and fluid mechanics problems. Uintah has both an applications layer with its own programming model and a separate runtime system. While Uintah scales well today, it is necessary to address nodal performance portability in order for it to continue to do. Incrementally modifying Uintah to use the Kokkos performance portability library through prototyping experiments results in improved kernel performance by more than a factor of two.
2015
![]()
J. K. Holmen, A. Humphrey, M. Berzins.
“Exploring Use of the Reserved Core,” In High Performance Parallelism Pearls, Edited by J. Reinders and J. Jeffers, Elsevier, pp. 229-242. 2015.
DOI: 10.1016/b978-0-12-803819-2.00010-0
In this chapter, we illustrate benefits of thinking in terms of thread management techniques when using a centralized scheduler model along with interoperability of MPI and PThreads. This is facilitated through an exploration of thread placement strategies for an algorithm modeling radiative heat transfer with special attention to the 61st core. This algorithm plays a key role within the Uintah Computational Framework (UCF) and current efforts taking place at the University of Utah to model next-generation, large-scale clean coal boilers. In such simulations, this algorithm models the dominant form of heat transfer and consumes a large portion of compute time. Exemplified by a real-world example, this chapter presents our early efforts in porting a key portion of a scalability-centric codebase to the Intel ® Xeon PhiTM coprocessor. Specifically, this chapter presents results from our experiments profiling the native execution of a reverse Monte-Carlo ray tracing-based radiation model on a single coprocessor. These results demonstrate that our fastest run confiurations utilized the 61st core and that performance was not profoundly impacted when explicitly over-subscribing the coprocessor operating system thread. Additionally, this chapter presents a portion of radiation model source code, a MIC-centric UCF cross-compilation example, and less conventional thread management techniques for developers utilizing the PThreads threading model.
![]()
A. Humphrey, T. Harman, M. Berzins, P. Smith.
“A Scalable Algorithm for Radiative Heat Transfer Using Reverse Monte Carlo Ray Tracing,” In High Performance Computing, Lecture Notes in Computer Science, Vol. 9137, Edited by Kunkel, Julian M. and Ludwig, Thomas, Springer International Publishing, pp. 212-230. 2015.
ISBN: 978-3-319-20118-4
DOI: 10.1007/978-3-319-20119-1_16
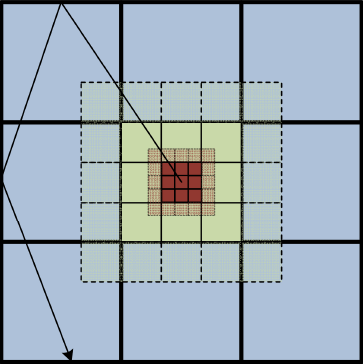
Keywords: Uintah; Radiation modeling; Parallel; Scalability; Adaptive mesh refinement; Simulation science; Titan
J.A. Nairn, J.E. Guilkey.
“Axisymmetric Form of the Generalized Interpolation Material Point Method,” In Int. J. for Numerical Methods in Engineering, Vol. 101, pp. 127-147. 2015.
DOI: 10.1002/nme.4792
This paper reformulates the axisymmetric form of the material point method (MPM) using generalized interpolation material point (GIMP) methods. The reformulation led to a need for new shape functions and gradients specific for axisymmetry that were not available before. The new shape functions differ most from planar shape functions near the origin where r=0. A second purpose for this paper was to evaluate the consequences of axisymmetry on a variety MPM extensions that have been developed since the original work on axisymmetric MPM. These extensions included convected particle domain integration (CPDI), traction boundary conditions, explicit cracks, multimaterial mode MPM for contact, thermal conduction, and solvent diffusion. Some examples show that the axisymmetric shape functions work well and are especially crucial near the origin. One real-world example is given for modeling a cylinder-penetration problem. Finally, a check list for software development describes all tasks needed to convert 2D planar or 3D codes to include an option for axisymmetric MPM.
![]()
B. Peterson, N. Xiao, J. Holmen, S. Chaganti, A. Pakki, J. Schmidt, D. Sunderland, A. Humphrey, M. Berzins.
“Developing Uintah’s Runtime System For Forthcoming Architectures,” Subtitled “Refereed paper presented at the RESPA 15 Workshop at SuperComputing 2015 Austin Texas,” SCI Institute, 2015.
![]()
B. Peterson, H. K. Dasari, A. Humphrey, J.C. Sutherland, T. Saad, M. Berzins.
“Reducing overhead in the Uintah framework to support short-lived tasks on GPU-heterogeneous architectures,” In Proceedings of the 5th International Workshop on Domain-Specific Languages and High-Level Frameworks for High Performance Computing (WOLFHPC'15), ACM, pp. 4:1-4:8. 2015.
DOI: 10.1145/2830018.2830023
2014
![]()
A. Dubey, A. Almgren, John Bell, M. Berzins, S. Brandt, G. Bryan, P. Colella, D. Graves, M. Lijewski, F. Löffler, B. O’Shea, E. Schnetter, B. Van Straalen, K. Weide.
“A survey of high level frameworks in block-structured adaptive mesh refinement packages,” In Journal of Parallel and Distributed Computing, 2014.
DOI: 10.1016/j.jpdc.2014.07.001
Over the last decade block-structured adaptive mesh refinement (SAMR) has found increasing use in large, publicly available codes and frameworks. SAMR frameworks have evolved along different paths. Some have stayed focused on specific domain areas, others have pursued a more general functionality, providing the building blocks for a larger variety of applications. In this survey paper we examine a representative set of SAMR packages and SAMR-based codes that have been in existence for half a decade or more, have a reasonably sized and active user base outside of their home institutions, and are publicly available. The set consists of a mix of SAMR packages and application codes that cover a broad range of scientific domains. We look at their high-level frameworks, their design trade-offs and their approach to dealing with the advent of radical changes in hardware architecture. The codes included in this survey are BoxLib, Cactus, Chombo, Enzo, FLASH, and Uintah.
Keywords: SAMR, BoxLib, Chombo, FLASH, Cactus, Enzo, Uintah
A. Faucett, T. Harman, T. Ameel.
“Computational Determination of the Modified Vortex Shedding Frequency for a Rigid, Truncated, Wall-Mounted Cylinder in Cross Flow,” In Volume 10: Micro- and Nano-Systems Engineering and Packaging, Montreal, ASME International Mechanical Engineering Congress and Exposition (IMECE), International Conference on Computational Science, November, 2014.
DOI: 10.1115/imece2014-39064
![]()
A. Humphrey, Q. Meng, M. Berzins, D. Caminha B.de Oliveira, Z. Rakamaric, G. Gopalakrishnan.
“Systematic Debugging Methods for Large-Scale HPC Computational Frameworks,” In Computing in Science Engineering, Vol. 16, No. 3, pp. 48--56. May, 2014.
ISSN: 1521-9615
DOI: 10.1109/MCSE.2014.11

Keywords: Computational Modeling and Frameworks, Parallel Programming, Reliability, Debugging Aids
![]()
Q. Meng, M. Berzins.
“Scalable large-scale fluid-structure interaction solvers in the Uintah framework via hybrid task-based parallelism algorithms,” In Concurrency and Computation: Practice and Experience, Vol. 26, No. 7, pp. 1388--1407. May, 2014.
DOI: 10.1002/cpe
Uintah is a software framework that provides an environment for solving fluid–structure interaction problems on structured adaptive grids for large-scale science and engineering problems involving the solution of partial differential equations. Uintah uses a combination of fluid flow solvers and particle-based methods for solids, together with adaptive meshing and a novel asynchronous task-based approach with fully automated load balancing. When applying Uintah to fluid–structure interaction problems, the combination of adaptive mesh- ing and the movement of structures through space present a formidable challenge in terms of achieving scalability on large-scale parallel computers. The Uintah approach to the growth of the number of core counts per socket together with the prospect of less memory per core is to adopt a model that uses MPI to communicate between nodes and a shared memory model on-node so as to achieve scalability on large-scale systems. For this approach to be successful, it is necessary to design data structures that large numbers of cores can simultaneously access without contention. This scalability challenge is addressed here for Uintah, by the development of new hybrid runtime and scheduling algorithms combined with novel lock-free data structures, making it possible for Uintah to achieve excellent scalability for a challenging fluid–structure problem with mesh refinement on as many as 260K cores.
Keywords: MPI, threads, Uintah, many core, lock free, fluid-structure interaction, c-safe
![]()
Qingyu Meng.
“Large-Scale Distributed Runtime System for DAG-Based Computational Framework,” Note: Ph.D. in Computer Science, advisor Martin Berzins, School of Computing, University of Utah, August, 2014.
Recent trends in high performance computing present larger and more diverse computers using multicore nodes possibly with accelerators and/or coprocessors and reduced memory. These changes pose formidable challenges for applications code to attain scalability. Software frameworks that execute machine-independent applications code using a runtime system that shields users from architectural complexities offer a portable solution for easy programming. The Uintah framework, for example, solves a broad class of large-scale problems on structured adaptive grids using fluid-flow solvers coupled with particle-based solids methods. However, the original Uintah code had limited scalability as tasks were run in a predefined order based solely on static analysis of the task graph and used only message passing interface (MPI) for parallelism. By using a new hybrid multithread and MPI runtime system, this research has made it possible for Uintah to scale to 700K central processing unit (CPU) cores when solving challenging fluid-structure interaction problems. Those problems often involve moving objects with adaptive mesh refinement and thus with highly variable and unpredictable work patterns. This research has also demonstrated an ability to run capability jobs on the heterogeneous systems with Nvidia graphics processing unit (GPU) accelerators or Intel Xeon Phi coprocessors. The new runtime system for Uintah executes directed acyclic graphs of computational tasks with a scalable asynchronous and dynamic runtime system for multicore CPUs and/or accelerators/coprocessors on a node. Uintah's clear separation between application and runtime code has led to scalability increases without significant changes to application code. This research concludes that the adaptive directed acyclic graph (DAG)-based approach provides a very powerful abstraction for solving challenging multiscale multiphysics engineering problems. Excellent scalability with regard to the different processors and communications performance are achieved on some of the largest and most powerful computers available today.
![]()
D.C.B. de Oliveira, A. Humphrey, Q. Meng, Z. Rakamaric, M. Berzins, G. Gopalakrishnan.
“Systematic Debugging of Concurrent Systems Using Coalesced Stack Trace Graphs,” In Proceedings of the 27th International Workshop on Languages and Compilers for Parallel Computing (LCPC), September, 2014.
A central need during software development of large-scale parallel systems is tools that help help to identify the root causes of bugs quickly. Given the massive scale of these systems, tools that highlight changes--say introduced across software versions or their operating conditions (e.g., inputs, schedules)--can prove to be highly effective in practice. Conventional debuggers, while good at presenting details at the problem-site (e.g., crash), often omit contextual information to identify the root causes of the bug. We present a new approach to collect and coalesce stack traces, leading to an efficient summary display of salient system control flow differences in a graphical form called Coalesced Stack Trace Graphs (CSTG). CSTGs have helped us understand and debug situations within a computational framework called Uintah that has been deployed at large scale, and undergoes frequent version updates. In this paper, we detail CSTGs through case studies in the context of Uintah where unexpected behaviors caused by different vesions of software or occurring across different time-steps of a system (e.g., due to non-determinism) are debugged. We show that CSTG also gives conventional debuggers a far more productive and guided role to play.
R. Stoll, E. Pardyjak, J.J. Kim, T. Harman, A.N. Hayati.
“An inter-model comparison of three computation fluid dynamics techniques for step-up and step-down street canyon flows,” In ASME FEDSM/ICNMM symposium on urban fluid mechanics, August, 2014.
2013
![]()
J. Beckvermit, J. Peterson, T. Harman, S. Bardenhagen, C. Wight, Q. Meng, M. Berzins.
“Multiscale Modeling of Accidental Explosions and Detonations,” In Computing in Science and Engineering, Vol. 15, No. 4, pp. 76--86. 2013.
DOI: 10.1109/MCSE.2013.89

Accidental explosions are exceptionally dangerous and costly, both in lives and money. Regarding world-wide conflict with small arms and light weapons, the Small Arms Survey has recorded over 297 accidental explosions in munitions depots across the world that have resulted in thousands of deaths and billions of dollars in damage in the past decade alone [45]. As the recent fertilizer plant explosion that killed 15 people in West, Texas demonstrates, accidental explosions are not limited to military operations. Transportation accidents also pose risks, as illustrated by the occasional train derailment/explosion in the nightly news, or the semi-truck explosion detailed in the following section. Unlike other industrial accident scenarios, explosions can easily affect the general public, a dramatic example being the PEPCON disaster in 1988, where windows were shattered, doors blown off their hinges, and flying glass and debris caused injuries up to 10 miles away.
While the relative rarity of accidental explosions speaks well of our understanding to date, their violence rightly gives us pause. A better understanding of these materials is clearly still needed, but a significant barrier is the complexity of these materials and the various length scales involved. In typical military applications, explosives are known to be ignited by the coalescence of hot spots which occur on micrometer scales. Whether this reaction remains a deflagration (burning) or builds to a detonation depends both on the stimulus and the boundary conditions or level of confinement. Boundary conditions are typically on the scale of engineered parts, approximately meters. Additional dangers are present at the scale of trucks and factories. The interaction of various entities, such as barrels of fertilizer or crates of detonators, admits the possibility of a sympathetic detonation, i.e. the unintended detonation of one entity by the explosion of another, generally caused by an explosive shock wave or blast fragments.
While experimental work has been and will continue to be critical to developing our fundamental understanding of explosive initiation, de agration and detonation, there is no practical way to comprehensively assess safety on the scale of trucks and factories experimentally. The scenarios are too diverse and the costs too great. Numerical simulation provides a complementary tool that, with the steadily increasing computational power of the past decades, makes simulations at this scale begin to look plausible. Simulations at both the micrometer scale, the "mesoscale", and at the scale of engineered parts, the "macro-scale", have been contributing increasingly to our understanding of these materials. Still, simulations on this scale require both massively parallel computational infrastructure and selective sampling of mesoscale response, i.e. advanced computational tools and modeling. The computational framework Uintah [1] has been developed for exactly this purpose.
Keywords: uintah, c-safe, accidents, explosions, military computing, risk analysis
![]()
M. Berzins, J. Schmidt, Q. Meng, A. Humphrey.
“Past, Present, and Future Scalability of the Uintah Software,” In Proceedings of the Blue Waters Extreme Scaling Workshop 2012, pp. Article No.: 6. 2013.
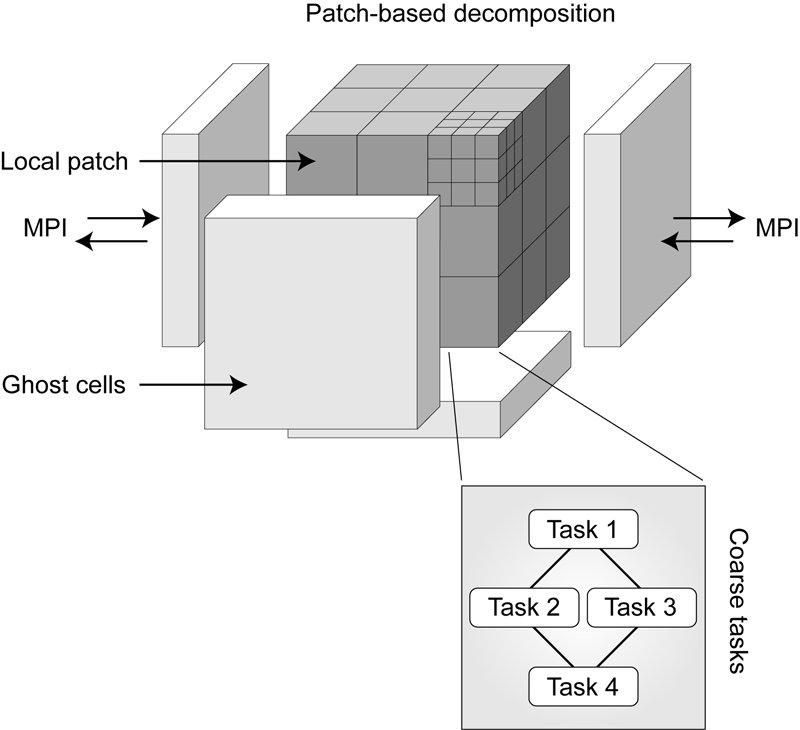
Keywords: netl, Uintah, parallelism, scalability, adaptive mesh refinement, linear equations
Page 2 of 14